
AI DLC Is Not SDLC With AI Bolted On (S2E4)
An article from the What The Tech (AU) podcast S2E4, expanding on our conversation with Gerardo Estaba — Solutions Architect at Supabase.

Software development is not just getting faster — It is changing shape.
That’s the unfashionable claim worth defending right now. Most engineering teams in Australia are running their AI work the way they’ve always run software — discovery, design, build, ship, maintain — with a faster autocomplete bolted on. They’re measuring the wrong things, hiring for the wrong skills, and spending money on the wrong models in the wrong phases.
On S02E04 of What The Tech, we sat down with Gerardo Estaba, Solutions Architect at Supabase, to dig into what is actually happening underneath the AI boom. The conversation kept circling back to the same uncomfortable observation: the Software Development Lifecycle as we knew it is being compressed into something with a fundamentally different geometry. And the teams who don’t see the shift are quietly losing.
We’re not the only ones saying it. EPAM has formalised it as the Agentic Development Lifecycle (ADLC) — “not SDLC augmented with AI coding assistants, but a lifecycle for building systems where LLMs sit at the core of product behaviour.”
Microsoft, IBM, and McKinsey have all published versions of the same observation since the start of 2026. The shift is real, named, and underway.
The conventional wisdom
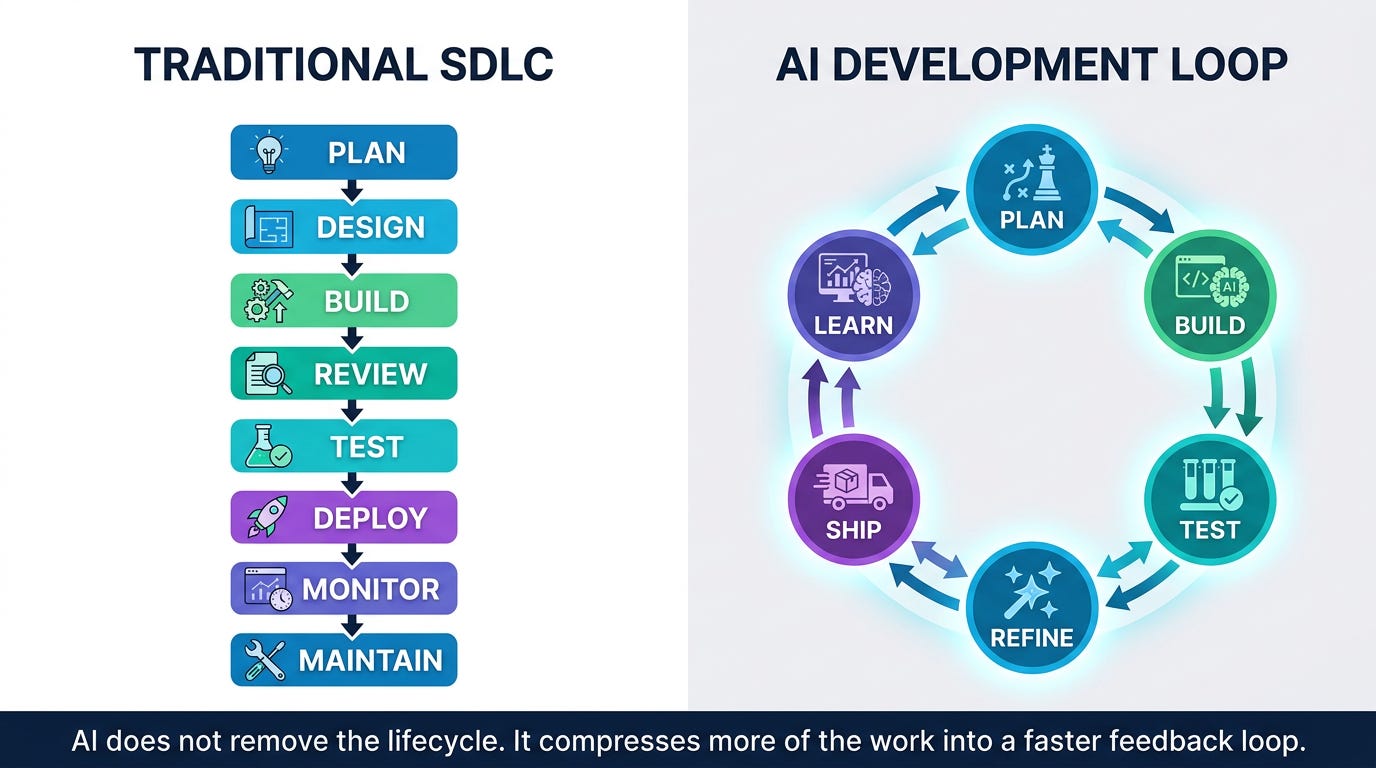
For two decades, the SDLC has been the default mental model for shipping software. Plan, design, architect, code, review, test, integrate, deploy, monitor, maintain — somewhere between 6 and 12 stages depending on whose diagram you’re looking at.
Each stage is a handover. Each handover is a meeting. Each meeting is a new feature. The lifecycle wasn’t really about the software — it was about coordinating the people building it.
When AI arrived, most teams reached for the obvious framing: (1) code completion in the build phase, (2) AI-assisted review in the review phase, (3) synthesised tests in the test phase.
McKinsey puts the productivity, code-quality, and delivery-timeline gain at 20-45% when AI is integrated this way. Real numbers but they describe a faster version of the old shape.
That framing isn’t wrong, it’s just incomplete.

Why it’s incomplete
The handovers were never overhead. They were the lifecycle. The work that happens between phases — translating designs into specs, specs into code, code into tests, tests into deployments — is what most of the SDLC actually represents.
When the handovers collapse, the stages collapse with them.
On the episode, Rene put it like this:
“If you look at the software development lifecycle, you have so many bubbles, so many circles you have to go through. The AI development lifecycle is like two circles.”
Gerardo’s response was the part that matters:
“In the past, you always needed a team of engineers — 14 engineers — in order to do a thing. Now you have one person and all these tools.”
If you don’t have 14 engineers, you don’t need 14 handovers. And if you don’t need 14 handovers, most of the stages those handovers existed to connect simply stop earning their keep.
The work didn’t disappear. It got absorbed into the loop:
Review still happens: inside the editor, before the PR is raised
Documentation still happens: generated alongside the code, not after
Test scaffolding still happens: written in the same prompt as the feature
Security checks still happen: flagged at prompt time, not at audit time
What looks like two circles from the outside is doing the same work as twelve. Concurrently, rather than sequentially. This is what EPAM means when they say ADLC isn’t SDLC-plus-AI — it’s a different lifecycle for systems whose behaviour is non-deterministic and evolves continuously after deployment.
The new frame
The interesting question is no longer which stages of the SDLC survive in the AI era. The interesting question is which model you pick for what’s happening inside each steps.
This is where most teams are getting it wrong — and it’s where Gerardo was sharpest on the episode. Three phases, three different optimisation problems.
Plan with the smartest model you can afford
Most teams underspend on planning. They reach for whatever model is cheapest, run a quick scoping pass, and start coding.
“When you’re coding, you probably want to use the most advanced model during your planning session. You want that plan, the strategy, and those choices that you make early in the beginning — before you write a single line of code — to be rock solid. So in planning mode, yes, go for the most expensive one.”
Every wrong architectural choice in planning compounds. The smartest models — currently Claude Opus 4.7, GPT-5.4, or whatever’s leading the reasoning charts the week you’re reading this — have the highest chance of catching the wrong call before a single line of code gets written. This is exactly where saving $20 in tokens costs $20,000 in rework.
Plan once. Plan well. Let the cheaper models handle the rest.
Build with the cheapest model that still works
Most teams overspend on the build phase. Long coding sessions on top-tier models burn budget and add latency for output a mid-tier model would have produced cleanly.
“The top models for both OpenAI and Anthropic cost five times what the second best does. And the differences in terms of what they achieve is small.”
A useful fact-check: Anthropic’s current lineup has narrowed that gap considerably since older Opus pricing. Opus 4.7 sits at $5/$25 per million tokens, Sonnet 4.6 at $3/$15, and Haiku 4.5 at $1/$5 — so the flagship-to-mid-tier ratio is now closer to 1.7x. The 5x ratio still applies, but it’s now flagship-to-budget (Opus to Haiku). The principle Gerardo is pointing at holds: most build-phase work doesn’t need flagship reasoning, and the savings from routing down a tier are real and measurable.
How real? A March 2026 routing study by Augment Code found that three-tier Claude routing saves 51% versus uniform deployment of the flagship model. CloudZero’s range across customer deployments is 40-60% spend reduction with no measurable quality loss on routed tasks. This is one of the highest-leverage cost decisions in any AI deployment, and most teams aren’t making it deliberately.
Gerardo flagged Anthropic’s Claude Code as a common default for the teams he works with — “Claude Code is becoming the standard coding agent” — partly because the tiered model selection inside it (Opus / Sonnet / Haiku) maps cleanly to this kind of phase-aware workflow. Plan with the top tier. Build with the cheap tier. Whatever the equivalents are in the model family you’ve standardised on.
Ship with the model your users can afford
The step that matters — production — runs on a completely different optimisation function.
“When you deploy and break into production, having the best model out there is not going to help you deliver more value to customers necessarily. Those bigger models might be smarter, but they take longer and they cost significantly more.”
“The most popular models in production are almost never the smartest one.”
In production you’re not solving for smartest. You’re solving for cost, latency, availability, and scalability. A model that nails the answer 100% of the time in 30 seconds is unusable. A model that nails it 95% of the time in 800 milliseconds is a product.
The teams shipping AI well in Australia are quietly running three or four model tiers in production, routed by the actual nature of each request — benchmark for the use case, not the leaderboard; build fallbacks for capacity ceilings; design for cost-per-interaction, not cost-per-token.
What doesn’t compress
The reframe has a hard edge. Some things in the lifecycle didn’t get easier — they got more important.
“The foundations haven’t gone anywhere. The foundations are even more important than ever.”
When one person and an AI agent can ship in days what used to take a team an entire quarter, the foundations carry an outsized share of the risk. Security cannot be prompted into existence. It has to live at the data layer — access controls, row-level security, audit logs, infrastructure-grade guardrails. Not bolted on later as policy.
The pattern is: speed up everything you can; slow down deliberately on the few things that have to survive contact with real users.
What this means for the tooling
The most visible casualty of the lifecycle change is the entire category of collaboration tools built for the old shape.
“This is why Atlassian — one of the biggest, probably the first unicorn out of Australia — they’re not doing so well. They have all these development tools that are built for humans.”
At the time of recording, the market agreed: Atlassian’s stock had fallen 87% from its 2021 peak, hitting an all-time low near $57 in April 2026. Since then, the picture has gotten more nuanced — the company is leaning hard into the shift Gerardo describes. Rovo, Atlassian’s agentic AI layer, has crossed 5 million monthly active users, Q3 FY26 revenue grew 32% year-over-year, and the stock has rebounded roughly 30% off its lows.
But that rebound proves the underlying point. Even one of the most successful incumbent software companies in Australia is being forced to fundamentally retool its developer tools for a world where teams are smaller and lifecycles are shorter. The companies that don’t pivot this hard are the ones genuinely in trouble.
For Australian product builders this is both a warning and an eye-opening. The incumbents built around the twelve-circle lifecycle are being forced to redesign for less steps, and the white space for tools designed natively for AI-DLC has barely been touched.
The delivery
The AI development lifecycle is two circles, not twelve.
Inside the first circle: plan with the best model you can afford, build with the cheapest one that still works. Inside the second: ship with the model your users can afford, and hold the foundations that the speed depends on.
That’s the whole game. The teams in Australia running their AI work this way are quietly extracting 40-60% cost savings without giving up quality, shipping in weeks what used to take quarters, and building on foundations that survive contact with real users. The ones still running the old SDLC with AI bolted on top are paying flagship prices for build-phase work, leaving routing savings on the table, and discovering at scale what their foundations should have done in week one.

Listen to the full episode
In S02E04 of What The Tech, we explore:
Why the AI development lifecycle compresses into two circles, not twelve
How to choose the right model for each phase — plan, build, ship
What doesn’t compress, and why foundations matter more than ever
Why traditional collaboration tools are struggling to keep up
What software development might look like five years from now
🎧 Listen on:
📬 Subscribe on Substack for episode breakdowns, reflections, and behind-the-scenes thinking.
Question for readers
Inside the two circles — Which one is quietly burning your budget?